搜索引擎发展史及工作原理
学习seo我觉得首先应该对搜索引擎的发展史及工作原理有一个了解,就像你学习任何一门技术,首先都会讲一下它的发展史及工作原理,如果你对它的工作原理都不了解,是无法继续深入的
搜索引擎发展史经历了四代
1:分类目录时代
2: 文本检索时代
3: 整合分析时代
4: 用户中心时代
第一代:分类目录
不知道大家在自己的电脑上是否有设置过导航网站作为自己的首页?其实这个网址就是搜索引擎第一代的代表。我们可以从这个导航网站里面看到,里面几乎都是一些分类网址,从这里我们可以看出,这个网站是一个导航网站,也可以说分类目录网站,用户可以从这个分类目录里找到自己想要的东西,这就是搜索引擎第一代分类目录,代表作如:www.hao123.com

第二代:文本检索时代
文本检索时代,搜索引擎查询信息的方法则是通过用户所输入的查询信息提交给服务器,服务器通过查阅,返回给用户一些相关程度高的信息。这就是搜索引擎第二代
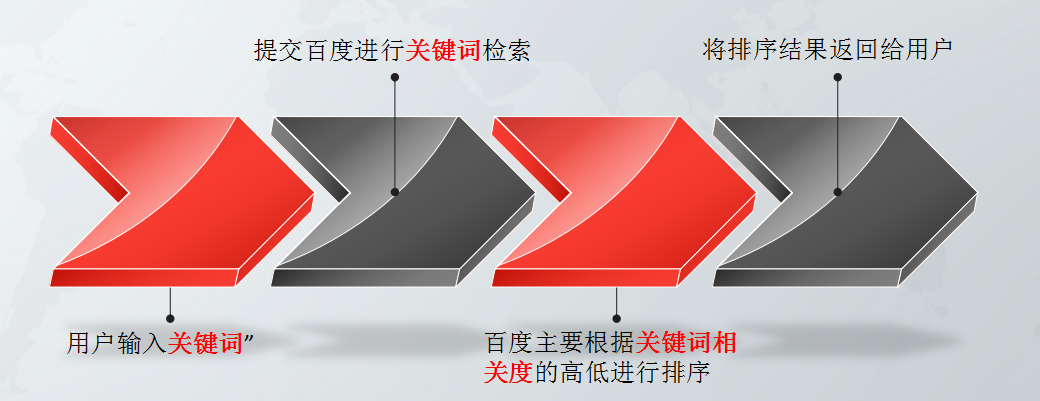
第三代:整合分析时代
整合分析时代的搜索引擎所使用的方法大概是和我们今天的网站的外部链接形式基本相同,在当时,外部链接代表的是一种推荐的含义,通过每个网站的推荐链接的数量来判断一个网站的流行性和重要性。然后搜索引擎再结合网页内容的重要性来和相似程度来改善用户搜索的信息质量
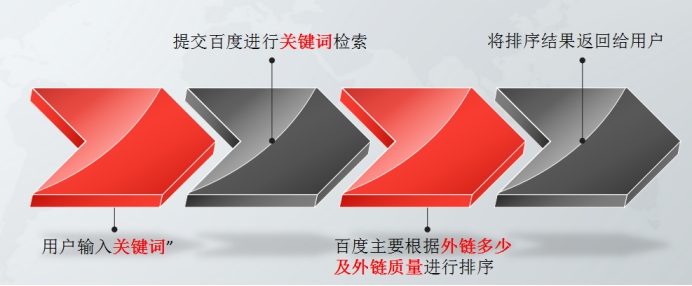
第四代:用户中心时代
当用户输入查询的请求时候,同一个查询的请求关键词在用户的背后可能是不同查询要求。例如用户输入的是“苹果”,那么作为一个想要购买iPhone的用户和一个果农来说,那么要求就是大大的不一样。甚至是同一个用户,所查询的关键词一样,也会因为所在的时间和所在的场合不同而返回的结果不同,所有主流搜索引擎都在致力于解决同一个问题:怎样才能从用户所输入的一个简短的关键词来判断用户的真正查询请求。这一代搜索引擎主要是以用户为中心。这就是用户中心时代
搜索引擎工作原理
1:抓取建库
2:检索排序
3:外部投票
4:结果展现
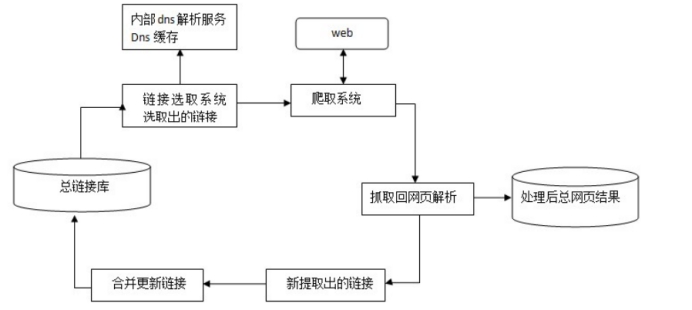
第一步:抓取建库
首先搜索引擎爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页,搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引, 流程如下图:
第二步:检索排序
如果能知道用户查找的关键词(query(查询)切词后)都出现在哪些页面中,那么用户检索的处理过程即可以想象为包含了query(查询)中切词后不同部分的页面集合求交的过程,而检索即变成了页面名称之间的比较、求交。这样,在毫秒内以亿为单位的检索成为了可能。这就是通常所说的倒排索引及求交检索的过程。如下为建立倒排索引的基本过程:
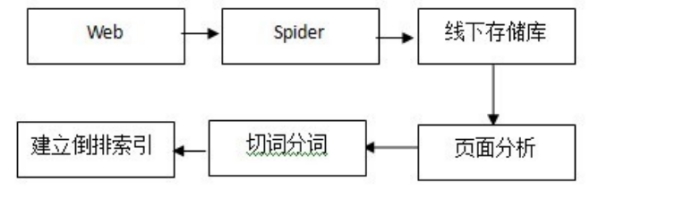
页面分析的过程实际上是将原始页面的不同部分进行识别并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等,分词的过程实际上包括了切词分词同义词转换同义词替换等等,以对某页面title分词为例,得到的将是这样的数据:term文本、termid(标识)、词类、词性等等,之前的准备工作完成后,接下来即是建立倒排索引,形成{termàdoc}(文档集合),下图即是索引系统中的倒排索引过程
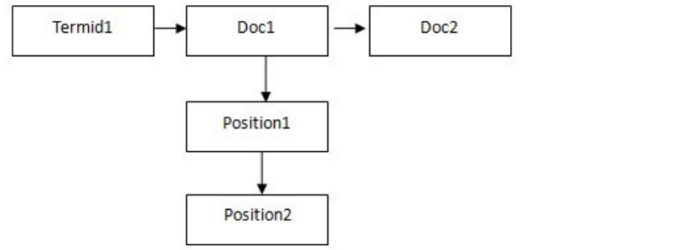
索引系统在建立倒排索引的最后还需要有一个入库写库的过程,而为了提高效率这个过程还需要将全部term以及偏移量保存在文件头部,并且对数据进行压缩,这涉及到的过于技术化在此就不多提了。在此简要给大家介绍一下索引之后的检索系统
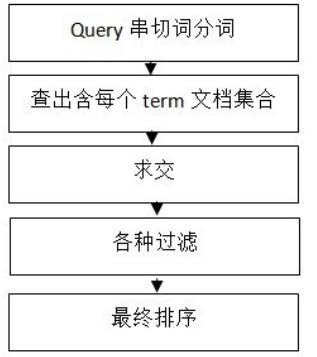
(1) Query串切词分词即将用户的查询词进行分词,对之后的查询做准备,以“10号线地铁故障”为例,可能的分词如下:
10 0x123abc
号 0x13445d
线 0x234d
地铁 0x145cf
故障 0x354df
(2)查出含每个term的文档集合,即找出待选集合,如下:
10 1 2 3 4 7 9…..
号 2 5 8 9 10 11……
(3)求交,上述求交,文档2和文档9可能是我们需要找的,整个求交过程实际上关系着整个系统的性能,这里面包含了使用缓存等等手段进行性能优化;
(4)各种过滤,举例可能包含过滤掉死链、重复数据、色情、垃圾结果以及你懂的;
(5)最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等
第三步:外部投票
曾经,“内容为王超链为皇”的说法流行了很多年,通过超链计算得分来体现网页的相关性和重要性,的确曾经是搜索引擎用来评估网页的重要参考因素之一,会直接参与搜索结果排序计算。但随着该技术被越来越多的SEO人员了解,超链已经逐渐失去作为投票的重要意义,无论是谷歌还是百度,对超链数据的依赖程度都越来越低。那么,在现在,超链在发挥着怎样的作用?
1, 吸引蜘蛛抓取:虽然百度在挖掘新好站点方面下了很大工夫,开放了多个数据提交入口,开避了社会化发现渠道,但超链依然是发现收录链接的最重要入口。
2, 向搜索引擎传递相关性信息:百度除了通过TITLE、页面关键词、H标签等对网页内容进行判断外,还会通过锚文本进行铺助判断。使用图片作为点击入口的超链,也可以通过alt属性和title标签向百度传情达意。
3, 提升排名:百度搜索引擎虽然降低了对超链的依赖,但对超链的识别力度从未下降,制定出更加严格的优质链接、正常链接、垃圾链接和作弊链接标准。对于作弊链接,除了对链接进行过滤清理外,也对链接的受益站进行一定程度的惩罚。相应的,对优质链接,百度依然持欢迎的态度。
4, 内容分享,获取口碑:优质内容被广泛传播,网站借此获得的流量可能并不多,但如果内容做得足够,也可以树立自己的品牌效应。*严格来讲,这并不属于超链的作用。在百度眼里,网站的品牌比超链要重要得多。
第四步:结果展现
这一步看似简单,其实是最复杂难度最大的,从我们输入搜索词到我们看到的结果,中间经历了非常多的计算.包含了前面三步,抓取建库,检索排序,外部投票.但我们看到的仅仅是搜索引擎返回给我们一个搜索结果展现,这里就不再多说了,了解即可