百度蛛蛛抓取策略分析以及如何识别百度蛛蛛
百度蛛蛛是一套专门用于从互联上抓取下载网页的程序,它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。
百度蛛蛛分类:
网页搜索 Baiduspider
无线搜索 Baiduspider
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
竞价蜘蛛Baiduspider-sfkr
百度蛛蛛抓取策略:
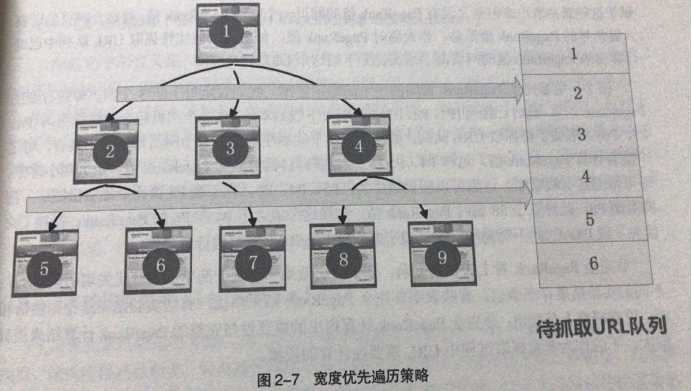
1:宽度优先遍历策略
举个简单的例子,a网页里面包含了b,c,d三个网页,b,c,d分别又包含了e,f,g三个网页,那么蛛蛛首页抓取a网页,然后再抓取b,c,d三个网页,最后再抓取e,f,g三个网页,这就是宽度优先遍历策略
2:深度优先策略
和宽度优先遍历策略刚好相反,比方说a网页包含b,c两个网页,b网页又包含d网页,c网页包含e网页,那么深度优先策略就是先抓取b网页再抓取b网页下面的d网页,完了再去抓取c网页
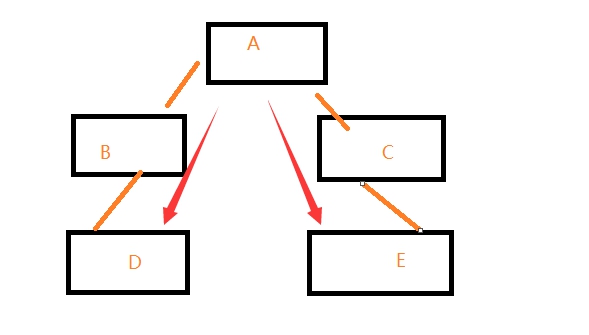
3:大站优先策略
大站优先策略就是一些门户网站,高权重网站(百度蛛蛛出发站点,种子站点)百度蛛蛛会优先进行一个抓取,这就是所谓的特权吧
4:还有“非完全PageRank策略”和“OPIC策略”这里就不再多说了,有兴趣可以自己去看一些相关书籍或者百度搜索
百度的蛛蛛的分析:
可以使用光年日志等工具对百度蛛蛛抓取的日志进行一个分析,从分析结果可以看出百度蛛蛛的访问频率,访问了哪些页面,也可以看出访问的时候是否出现一些错误,比如404,502等等
如何识别百度蛛蛛
1、查看UA,如果UA都不对,可以直接判断非百度搜索的蜘蛛,目前对外公布过的UA是:
移动UA:Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
PC UA:Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
新增渲染UA:
移动UA:Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 likeMac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)
PC UA:Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)